



AI로 음악 콘서트홀과 거의 유사한 음을 들을 수 있다면 DEEP LEARNING COULD BRING THE CONCERT EXPERIENCE HOME




Construction, Science, IT, Energy and all other issues
Search for useful information through the top search bar on blog!
건설,과학,IT, 에너지 외 국내외 실시간 종합 관심 이슈 발행
[10만이 넘는 풍부한 데이터베이스]
블로그 맨 위 상단 검색창 통해 유용한 정보를 검색해 보세요!
[경과]
원음에 가까운 음을 듣기 위한 세계 최고의 스피커 시스템
Transmission Audio Ultimate
Estimated: $1.2 Million

AI
3D Soundstage
"150년의 개발 기간이 지난 지금도 고급 오디오 시스템에서 들리는 소리는 우리가 라이브 음악 공연에 물리적으로 있을 때 들을 수 있는 소리와는 거리가 멀다."
우리의 스마트폰, 스마트 스피커, TV, 라디오, 디스크 플레이어, 그리고 자동차 사운드 시스템에서, 그것은 우리의 삶에서 지속적이고 즐거운 존재다. 2017년, 닐슨의 조사에 따르면 미국 인구의 약 90%가 정기적으로 음악을 듣고 있으며, 평균적으로 일주일에 32시간을 음악을 듣는다고 한다.

이 자유로운 흐름의 즐거움 뒤에는 가능한 한 사실적으로 소리를 재생한다는 오랜 목표에 기술을 적용하는 거대한 산업들이 있다. 에디슨의 축음기와 1880년대의 경음기 스피커로부터, 이 이상을 추구하는 연속적인 기술자 세대들은 수많은 기술들을 발명하고 이용했다: 3극 진공관, 다이나믹 스피커, 자기 축음기 카트리지, 다양한 토폴로지의 솔리드 스테이트 앰프 회로, 정전기 스피커, 광학 디스크, 스테레오, 그리고 서라운드 사운드. 그리고 지난 50년 동안, 오디오 압축과 스트리밍과 같은 디지털 기술은 음악 산업을 변화시켰다.
하지만, 150년의 개발 기간이 지난 지금도, 우리가 고급 오디오 시스템으로부터 들을 수 있는 소리는 우리가 라이브 음악 공연에 물리적으로 있을 때 들을 수 있는 것에 훨씬 못 미친다. 그러한 사건에서, 우리는 자연스러운 음장에 있고, 심지어 음장이 여러 악기의 혼합 음과 교차하는 경우에도 다른 악기의 소리가 다른 위치에서 나온다는 것을 쉽게 인식할 수 있다. 사람들이 라이브 음악을 듣기 위해 상당한 금액을 지불하는 이유가 있습니다. 그것은 더 즐겁고, 흥미롭고, 더 큰 감정적 영향을 일으킬 수 있다.
저자의 3D Soundstage 오디오를 직접 들으려면 헤드폰을 잡고 3dsoundstage.com/ieee으로 이동하십시오.
오늘날, 우리를 포함한 연구자, 회사, 그리고 기업가들은 마침내 진정으로 자연스러운 음장을 재창조하는 녹음된 오디오에 접근하고 있다. 이 그룹에는 애플과 소니와 같은 대기업과 크리에이티브와 같은 소규모 기업들이 포함되어 있다. 넷플릭스는 최근 센하이저와의 파트너십을 공개했는데, 이 네트워크는 "낯선 것들"과 "위처"와 같은 TV 쇼의 소닉 리얼리즘을 높이기 위해 새로운 시스템인 암베오 2채널 공간 오디오를 사용하기 시작했다.
이제 매우 사실적인 오디오를 생산하기 위한 적어도 6개의 다른 접근법이 있다. 우리는 "사운드 스테이지"라는 용어를 사용하여 우리의 작업을 공간 오디오 또는 몰입형 오디오와 같은 다른 오디오 형식과 구별한다. 이것들은 일반적인 스테레오보다 더 공간적인 효과를 가진 소리를 나타낼 수 있지만, 일반적으로 진정으로 설득력 있는 음장을 재생하는 데 필요한 상세한 음원 위치 신호를 포함하지 않는다.
우리는 사운드 무대가 음악 녹음과 재생산의 미래라고 믿는다. 그러나 그러한 전면적인 혁명이 일어나기 전에, 거대한 장애물을 극복하는 것이 필요할 것이다: 모노, 스테레오, 멀티채널 서라운드 사운드(5.1, 7.1 등)와 상관없이 기존 녹음의 수많은 시간을 편리하고 저렴하게 변환하는 것이다. 어느 누구도 얼마나 많은 노래가 녹음되었는지 정확히 알지 못하지만, 엔터테인먼트-메타데이터 관련 Gracenote에 따르면, 현재 지구에서 2억 개 이상의 녹음된 노래들을 이용할 수 있다. 한 곡의 평균 지속시간이 약 3분인 점을 감안하면 약 1100년 분량의 음악인 셈이다.
새로운 오디오 형식을 대중화하려는 어떠한 시도도, 아무리 유망하더라도, 우리가 현재 집에서, 해변에서, 기차에서, 또는 자동차에서 스테레오 음악을 즐기는 것과 같은 편리함과 편리함으로 이 모든 기존 오디오를 들을 수 있게 하는 기술이 포함되지 않는 한 실패할 수밖에 없다.
우리는 그런 기술을 개발했다. 우리가 3D Soundstage라고 부르는 이 시스템은 스마트폰, 일반 또는 스마트 스피커, 헤드폰, 이어폰, 노트북, TV, 사운드바, 차량 내에서도 사운드 스테이지에서 음악을 재생할 수 있다. 모노 및 스테레오 녹음을 사운드 스테이지로 변환할 수 있을 뿐만 아니라, 특별한 훈련 없이 청취자가 그래픽 사용자 인터페이스를 사용하여 자신의 취향에 따라 사운드 필드를 재구성할 수 있다. 예를 들어, 청취자는 각 악기 및 보컬 음원의 위치를 지정하고 각각의 음량을 조정하여 악기 반주에 비해 보컬의 상대 음량을 변경할 수 있다. 이 시스템은 인공지능(AI), 가상 현실 및 디지털 신호 처리(잠시 후 추가)를 활용하여 이를 수행한다.
예를 들어, 헤드폰 한 쌍에 있는 것과 같은 두 개의 작은 스피커에서 나오는 현악 4중주단에서 나오는 소리를 설득력 있게 재현하려면 상당한 기술적 기교가 필요하다. 이것이 어떻게 이루어지는지 이해하기 위해, 우리가 소리를 인식하는 방법부터 시작합시다.

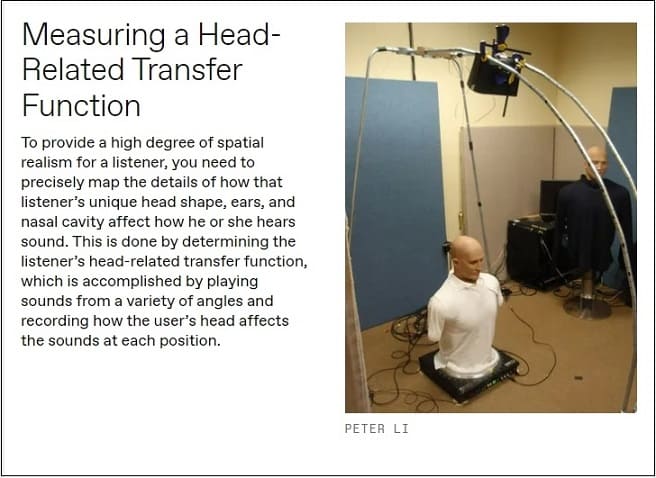
소리가 귀로 전달될 때, 머리의 독특한 특징들, 즉 물리적 모양, 바깥 귀와 안쪽 귀의 모양, 심지어 비강의 모양까지도 원래의 소리의 오디오 스펙트럼을 변화시킨다. 또한, 음원에서 당신의 두 귀까지의 도착 시간에 매우 작은 차이가 있다. 이 스펙트럼의 변화와 시차로부터, 여러분의 뇌는 음원의 위치를 인식한다. 스펙트럼 변화와 시간 차이는 머리 관련 전달 함수(HRTF)로 수학적으로 모델링할 수 있다. 머리 주위의 3차원 공간에 있는 각 점마다, 왼쪽 귀와 오른쪽 귀의 HRTF가 한 쌍씩 있다.
그래서, 오디오의 한 부분이 주어진다면, 우리는 한 쌍의 HRTF를 사용하여 그 오디오를 처리할 수 있다. 하나는 오른쪽 귀에, 다른 하나는 왼쪽 귀에. 원래의 경험을 재현하기 위해, 우리는 그것들을 녹음한 마이크에 대한 음원의 위치를 고려할 필요가 있을 것이다. 만약 우리가 그 처리된 오디오를 다시 재생한다면, 예를 들어 헤드폰 한 쌍을 통해, 청취자는 원래의 신호와 함께 오디오를 들을 것이고, 그 소리가 원래 녹음된 방향에서 오고 있다는 것을 인지할 것이다.
만약 우리가 원래의 위치 정보를 가지고 있지 않다면, 우리는 단순히 개별 음원에 대한 위치를 할당하고 본질적으로 같은 경험을 얻을 수 있다. 청취자는 연주자 배치의 사소한 변화를 눈치채지 못할 것이다. 실제로, 그들은 그들 자신의 구성을 선호할 수도 있다.
황기철 콘페이퍼 에디터 인플루언서
Ki Chul Hwang Conpaper editor influencer
(Source:
https://spectrum.ieee.org/3d-audio)
kcontents
