



Google 봇 크롤링은 'Core Web Vitals' 점수를 평가하지 않는다 Googlebot Doesn't Evaluate The Core Web Vitals; Chrome Does




Googlebot Doesn't Evaluate The Core Web Vitals; Chrome Does
Google's John Mueller pointed out an important fact that I see a lot of folks in the industry misunderstanding around core web vitals. Googlebot does crawl the web and brings in most of the signals Google uses to rank your pages, but the core web vitals do not come from Googlebot or crawling, it comes from the Chrome CRuX field data report.
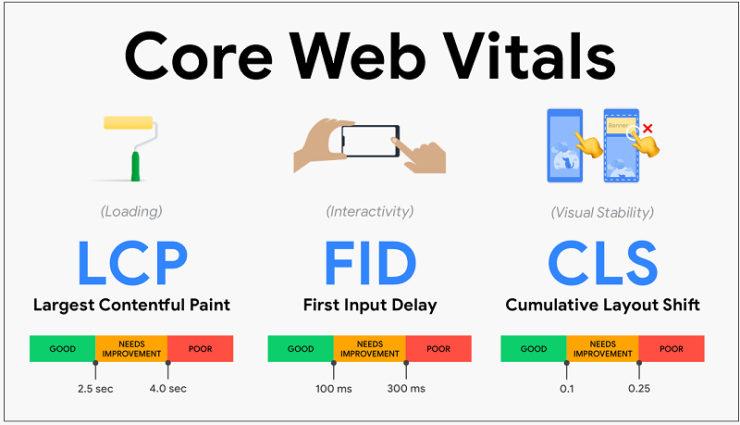
That means, Google uses real Chrome usage data to bring in data around the core web vitals about specific pages. That includes the LCP, FID, and CLS scores. Googlebot crawling is not the source Google is getting this data from. Chrome usage, a person visiting your site on a Chrome browser, is where Google is getting this data from.
You can learn more about the Chrome user experience report there if you want.
Here are John's tweets:

https://www.seroundtable.com/googlebot-doesnt-evaluate-the-core-web-vitals-31301.html
Google 봇은 '코어 웹 바이탈'을 평가하지 않으며 그것을 Chrome이 한다.
구글의 존 뮬러는 많은 사람들이 코어 웹 바이탈(Core Web Vitals)에 대해 오해하고 있다는 중요한 사실을 지적했다. 구글봇은 웹을 크롤링하며 구글이 당신의 페이지 순위를 매기기 위해 사용하는 대부분의 시그널을 가져오지만, 코어 웹 바이탈(Core Web Vitals)은 구글봇이나 크롬 CRuX 필드 데이터 보고서에서 나온 것이 아니다.
즉, Google은 실제 Chrome 사용 데이터를 사용하여 특정 페이지에 대한 코어 웹 바이탈(Core Web Vitals)에 대한 데이터를 가져온다. 여기에는 LCP, FID 및 CLS 점수가 포함된다. 구글봇 크롤링은 구글이 이 데이터를 얻는 출처가 아니다. 구글은 Chrome의 사용, Chrome 브라우저로 사이트를 방문하는 사람 등에서 데이터를 얻는다.
황기철 콘페이퍼 에디터
Ki Chul Hwang Conpaper editor
kcontents
