



오픈AI의 새로운 '이미지젠'...디자인 산업에 미칠 영향 Open AI Just Soloed Every Image Gen Platform. This is ABSURD.




OpenAI는 이미지 생성 인공지능 기능 “ChatGPT 이미지 젠”을 소개했습니다. 이 기능은 ChatGPT(대화형 AI)에 이미지 생성 능력을 통합한 것으로, GPT-4o 모델의 멀티모달 기술을 기반으로 합니다. 오늘은 이미지 젠의 주요 기능과 개선점, 작동 원리, 실제 생성 사례, 그리고 디자인 산업에 미칠 영향에 대해 정리를 해보겠습니다.
이미지 젠의 주요 기능
ChatGPT 이미지 젠은 기존 이미지 생성 AI들과 비교하여 텍스트 표현 정확도, 복잡한 장면 구성, 사용자 명령에 대한 정밀한 제어 측면에서 크게 향상되었습니다. 향상된 기능 덕분에, ChatGPT 이미지 젠은 사용자의 의도를 보다 정확히 시각화하고 “머릿속 이미지”에 가까운 결과물을 얻을 수 있게 해줍니다. 특히 이미지 내 텍스트(rendered text) 품질이 크게 개선되어, 메뉴판이나 로고의 글자도 또렷하고 제대로 표시할 수 있습니다. 또한 한 이미지 안에 다수의 객체가 등장하는 복잡한 장면에서도 각 객체의 속성(색상, 모양 등)을 정확히 지켜서 표현할 수 있어 디테일한 구성이 가능합니다. 이러한 발전으로 로고, 다이어그램, 인포그래픽 등 실용적인 디자인 이미지 생성에도 유용성이 높아졌습니다.

Open AI Just Soloed Every Image Gen Platform. This is ABSURD.
무엇보다 ChatGPT와 통합되었다는 점이 주목할 만합니다. 이미지 젠은 GPT-4o 모델에 내장된 이미지 생성기능으로, 이제 사용자가 대화하듯 이미지를 만들어내고 원하는 방향으로 수정할 수 있습니다. 예를 들어, 한 번 생성된 이미지에 대해 “배경을 밝게 변경해줘” 혹은 “다른 각도로 다시 그려봐”처럼 추가 지시를 내리면, ChatGPT가 해당 맥락을 이해하고 이미지를 재생성합니다. 이런 대화형 워크플로우는 사용자가 프롬프트를 처음부터 다시 작성하지 않고도 결과를 개선할 수 있게 해주며, 디자인 작업의 실험과 반복(iteration) 과정을 크게 편리하게 합니다.
또한 사용자는 직접 이미지를 업로드하여 참고자료로 활용할 수도 있습니다. 예컨대 UI 디자이너가 기존에 그려둔 드롭다운 메뉴 시안 이미지를 업로드한 뒤, ChatGPT에게 “이 스타일을 참고해 더 나은 메뉴 디자인을 만들어줘”라고 요청하면 AI가 해당 요소와 스타일을 분석해 개선된 이미지를 만들어냅니다. 이러한 참고 이미지 기반 생성과 더불어, 배경제거(transparent background) 기능으로 로고나 아이콘처럼 다른 그래픽에 겹쳐 쓸 수 있는 요소 디자인도 손쉽게 얻을 수 있습니다.
요약하면, ChatGPT 이미지 젠은 텍스트-투-이미지 변환 기술을 한 단계 끌어올려 정확성, 일관성, 제어 용이성을 갖춘 AI 도구입니다. 디자이너들은 이제 대화형 AI에게 말 걸듯 아이디어를 시각화하고, 필요하면 세밀한 수정까지 반영된 이미지를 얻을 수 있게 되었습니다.
작동 원리: 멀티모달 모델의 이미지 생성
이미지 젠(Image Gen) 기능의 핵심에는 OpenAI의 GPT-4o 모델, 즉 “GPT-4 옴니(Omni)”가 있습니다. GPT-4o는 텍스트뿐만 아니라 이미지와 음성까지 이해하고 생성할 수 있는 멀티모달 AI로, 2024년 4월에 공개된 OpenAI의 최신 플래그십 모델입니다. 이름의 “o”는 omni(모든 것)를 뜻하며, 실제로 GPT-4o는 텍스트, 오디오, 이미지, 비디오까지 입력으로 받고 텍스트, 음성, 이미지를 출력할 수 있는 범용 모델로 설계되었습니다. 이 중 이미지 생성 능력이 ChatGPT에 통합된 것이 바로 이미지 젠 기능입니다.

기존에는 ChatGPT가 이미지 생성 요청을 받으면 별도의 이미지 모델(DALL·E 등)을 호출해 결과를 받아오는 방식이었지만, GPT-4o에서는 텍스트와 이미지 생성이 하나의 모델에서 이루어집니다. 이미지 젠은 GPT-4o의 대화형 맥락 이해 능력과 이미지 합성 능력이 결합된 형태로 작동합니다. 이를 통해 언어와 시각 정보가 긴밀히 상호작용하는 새로운 방식을 보여주는데, 간단히 말하면 한 모델이 대화도 이해하고 바로 그림도 그리는 것입니다.
이 모델은 인터넷상의 방대한 이미지-텍스트 쌍 데이터와 파트너사 제공 이미지 등을 함께 학습하여, 텍스트와 이미지의 관계뿐 아니라 이미지들 간의 관계까지 터득했습니다. OpenAI 연구진은 “온라인상의 이미지와 텍스트의 조합분포(joint distribution)를 학습하여, 이미지와 언어의 연관성뿐 아니라 이미지들 사이의 관계까지 배웠다”*고 설명합니다. 이러한 훈련 덕분에 GPT-4o는 문맥을 고려한 일관성 있는 이미지 생성과 세계 지식에 기반한 사실적인 표현이 가능합니다. 예를 들어 사용자가 “뉴턴의 프리즘 실험 이미지”를 요청하면, 모델은 뉴턴과 프리즘에 대한 사전 지식을 활용해 별도의 설명 없이도 관련 다이어그램을 그려낼 수 있습니다. 이는 마치 사람이 풍부한 배경지식을 바탕으로 그림을 그리는 것과 유사합니다.
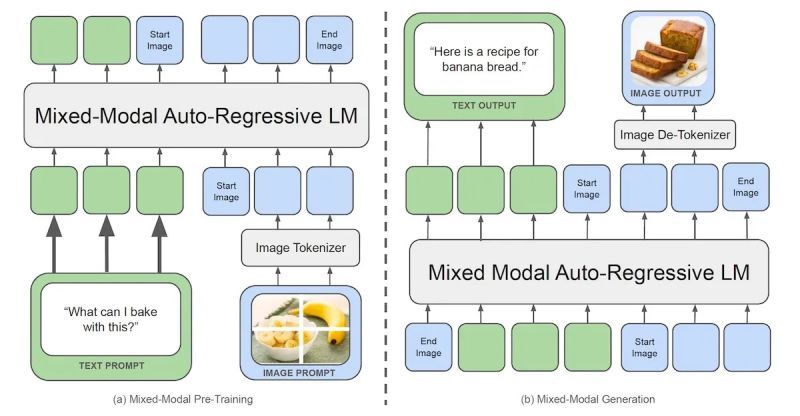
흥미로운 기술적 요소로, GPT-4o의 이미지 생성 방식은 기존 확산 모델(diffusion)과 달리 “자가회귀 방식(autoregressive approach)”을 사용한다는 점이 있습니다. 즉 이미지를 한 번에 통째로 그리는 대신, 왼쪽 위부터 오른쪽 아래로 차례로 그려나가는 방법을 택했습니다. 이러한 방식은 텍스트를 쓸 때 한 글자씩 써내려가는 것과 유사하며, 그 결과 이미지 내 텍스트의 철자 하나까지도 모델이 순차적으로 신경 쓰게 되어 글자 표현의 정확도가 향상되었습니다. 또한 객체들의 위치와 관계도 한 번에 뒤섞이지 않고 순차적으로 배치되기에 여러 객체의 복잡한 관계도 정확히 반영할 수 있습니다. OpenAI의 연구 책임자 Gabriel Goh는 “이번 모델은 기존보다 속성 바인딩(binding)이 우수하여 다수 객체의 모양·색상 관계를 잘 지킨다”며, 기존 모델들이 5~8개의 항목만 넘어가도 섞어 그리기 일쑤였던 한계를 극복했다고 밝혔습니다.
또한 이미지 젠은 대화 맥락을 지속적으로 활용합니다. 앞서 언급한 대로, 사용자가 여러 차례에 걸쳐 원하는 이미지를 구체화하면 모델은 이전 대화 내용과 생성했던 이미지들을 기억하고 일관성 있게 반영합니다. 예를 들어 비디오 게임 캐릭터 디자인을 한다고 가정하면, 첫 번째 시도에서 나온 캐릭터 모습을 토대로 다음 이미지에서도 같은 생김새와 색상을 유지하며 포즈나 배경만 바꾸는 식입니다. 이런 멀티턴(Multi-turn) 이미지 생성은 시리즈 일러스트나 스토리보드, 애니메이션 컨셉 작업에 특히 유용합니다.
정리하면, GPT-4o 기반의 이미지 젠은 “말하는 그림 도구”라 할 수 있습니다. 한 모델 안에서 언어 이해와 이미지 생성이 통합되어 동작하기 때문에, 사용자의 복잡한 의도나 참조 자료도 자연스럽게 시각화해줍니다. 이는 디자인 프로세스에서 사람 디자이너와 AI가 협업할 수 있는 새로운 가능성을 열어줍니다.
ChatGPT 이미지 젠이 만들어낸 디자인 사례
이미지 젠의 능력은 OpenAI가 공개한 여러 예시 이미지들에서 잘 드러납니다.
과학 인포그래픽
“뉴턴의 프리즘 실험을 상세히 설명하는 인포그래픽 이미지를 만들어줘.” 이 프롬프트에 대해 ChatGPT 이미지 젠은 프리즘 실험의 개요를 도식화한 그래픽을 생성했습니다. 아래 그림에서 볼 수 있듯, 빛이 프리즘을 통과해 스펙트럼으로 분산되는 과정을 설명하는 다이어그램에 정확한 레이블과 텍스트가 들어가 있습니다. “Incident light (입사광)”, “Glass prism (유리 프리즘)”, “Spectrum (스펙트럼)” 등 전문 용어가 오탈자 없이 명확히 표기되어 있고, 색상띠에는 실제 스펙트럼 색 이름(빨강~보라)이 제대로 적혀 있습니다. 이처럼 과학적 개념도를 손쉽게 생성할 수 있어, 교육 자료나 기술 문서에 활용하기 용이합니다.
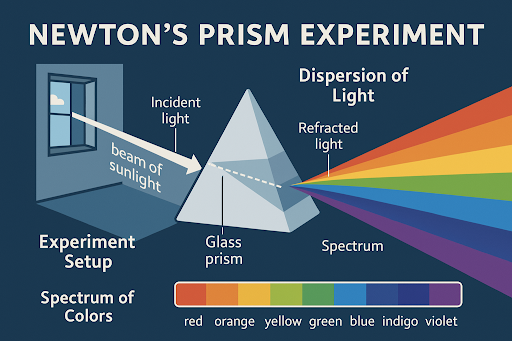
프롬프트: “뉴턴의 프리즘 실험을 자세히 설명하는 인포그래픽을 생성해줘.”
(결과: 실험 장치와 빛의 분산 과정을 보여주는 다이어그램 이미지 생성)
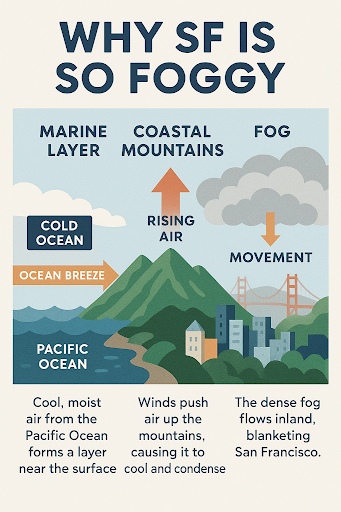
프롬프트: “샌프란시스코는 왜 항상 안개가 끼는지에 대한 이미지를 생성해"
(결과: 샌프란시스코의 안개와 관련된 도식화 이미지 생성)
멀티패널 만화/일러스트
이미지 젠은 스토리가 있는 만화 형식의 그림도 만들어낼 수 있습니다. OpenAI 팀은 내부 테스트로 4컷 만화를 제작해 보였는데, 일관된 캐릭터와 대사 텍스트까지 잘 담겼습니다. 예를 들어 한 시나리오에서는 “작은 달팽이가 스포츠카를 사러 와서 ‘차 문마다 S 글자를 크게 써달라’고 주문하고, 마지막 컷에서 S자가 잔뜩 그려진 빨간 스포츠카가 질주하자 사람들이 ‘와, S-car go(에스카고)!’라고 외치는 코믹 장면”을 프롬프트로 넣었는데, AI가 이 요구를 정확히 이해해 캐릭터의 표정, 말풍선 글자, 그리고 마지막의 말장난까지 완벽히 표현했습니다. 이 사례는 여러 장면에 걸친 시각적 스토리텔링과 텍스트 유머까지도 AI가 구현할 수 있음을 보여줍니다. 디자이너는 이를 활용해 짧은 홍보 만화, 콘티(cartoon storyboard), 연속 일러스트 등을 신속하게 얻을 수 있습니다.

프롬프트: “여백이 있는 4컷 만화를 그려줘. 1컷: 달팽이가 화려한 자동차 상점 카운터에 있고 판매원이 그를 내려다보고 있음... 4컷: 빨간 스포츠카에 커다란 S 글자들이 그려져 있고 사람들이 ‘와! 저기 S-car go 간다!’라고 말함.” (요약)
(결과: 지시한 내용대로 4개의 장면이 순서대로 구성된 만화 이미지 생성, 말풍선 포함)
제품 디자인 및 광고 시각화
제품 컨셉이나 광고 이미지도 대화형 프롬프트로 만들어낼 수 있습니다. 한 예로, 사용자 요청으로 “파란색 전기톱(chainsaw)을 현실감 있게 보여줘”라고 하면 고해상도의 제품 이미지를 생성한 뒤, 이어서 “이 전기톱을 활용한 재미있는 광고 이미지를 만들어줘: 추수감사절 저녁 식탁에서 할머니가 전기톱으로 칠면조를 썬다 – 태그라인도 넣어줘”와 같은 추가 지시를 내릴 수 있습니다. 그러면 이미지 젠은 앞서 만든 전기톱 이미지를 참고하여, 식탁 풍경 속에 그 전기톱을 들고 있는 할머니와 놀라는 가족들, 그리고 재치 있는 광고 카피까지 들어간 유머러스한 광고 장면을 만들어줍니다. 이렇게 연속된 맥락을 유지하며 창의적인 연출을 더하는 능력은, 제품 시연 이미지나 콘셉트 광고를 구상할 때 매우 유용합니다. 또한 생성 결과물에서 배경을 투명하게 처리하도록 지시하면 제품만 분리된 PNG 이미지로 얻을 수도 있어, 후속 편집이나 프레젠테이션 목업(mockup)에 바로 활용할 수 있습니다.

프롬프트 예시: “예술 작품에 활용할 수 있는 포스터를 그려줘.”
(결과: 미트색 배경에 예술 작품이 포함된 포스터 이미지)

프롬프트 예시: “맛차 만드는 방법을 그림으로 그려줘.”
(결과: 일관된 이미지의 맛차 만드는 일러스트 이미지)
이상의 사례들에서 보듯, ChatGPT 이미지 젠은 그래픽 디자인, 일러스트레이션, 제품 컨셉 아트, 등 다양한 디자인 영역에서 창의적인 결과물을 보여주고 있습니다. 중요한 점은, 디자이너의 텍스트 아이디어만 있으면 즉각적인 시각화가 가능하다는 것이며, 이는 초기 컨셉 구상 단계에서부터 시안(Mockup) 제작에 이르기까지 폭넓게 활용될 수 있습니다.
디자인 산업에 미칠 영향
기존에 미드저니가 디자인 분야에 끼친 영향 만큼은 아니지만 ChatGPT 이미지 젠의 등장은 디자인 산업에도 계속적인 변화를 가져오는 촉매제가 될 것으로 보입니다.
아이디어 발상과 개념 시각화의 가속화: 개념적이고 텍스트가 들어가야 하는 아이데이션이나 시각화 작업에서도 AI를 활용할 수 있게 되었기 때문에 초기 디자인 단계에서 아주 효과적으로 활용이 될 수 있습니다.
시안 제작과 의사소통 개선: 디자인 시안을 만들고 공유하는 과정도 효율화됩니다. 텍스트가 포함된 디자인 시한을 바로 제작할 수 있기 때문에 포스터, 일러스트 작업 등에 새로운 파급력을 끼칠 것으로 보입니다.
새로운 디자인 역할: AI의 성능이 과도하게 좋아지면서 일반인들도 텍스트 프롬프트 만으로 왠만큼 괜찮은 시안들을 쉽게 만들 수 있게 되었습니다. 디자이너들은 보다 고차원적인 이미지와 디테일한 조정을 할 수 있는 프롬프트 엔지니어링 능력과 자신만의 브랜딩 능력을 갖추는 것이 더 중요해지고 있습니다.
결론적으로 ChatGPT 이미지 젠은 기존에 AI가 이미지 생성 뿐 아니라 개념적인 영역들을 시각화하는데에도 큰 영향을 끼쳐 AI를 활용한 디자인 작업에 더 큰 파장을 가져올 것입니다. 이제 디자이너의 AI 활용 능력은 필수 불가결한 역량이 되었음을 보게 됩니다. 살아 남는 디자이너가 되기 위해서는 지속적으로 공부하여 AI 리터러시를 향상 시키고 이를 기반으로 디자인 작업을 할 수 있는 역량을 갖춰 나가야 하겠습니다.
brunch.co.kr/@ghidesigner/211
Open AI Just Soloed Every Image Gen Platform. This is ABSURD.
kconetnts
